구글과 오픈AI가 최근 공개한 최신 인공지능(AI) 모델들이 성능 향상에도 불구하고 안전성 측면에서 우려를 낳고 있다. 특히, 구글의 ‘제미나이 2.5 플래시(Gemini 2.5 Flash)’와 오픈AI의 ‘o3’ 및 ‘o4-미니(o4-mini)’ 모델은 이전 버전보다 안전성 평가에서 낮은 점수를 받은 것으로 나타났다.
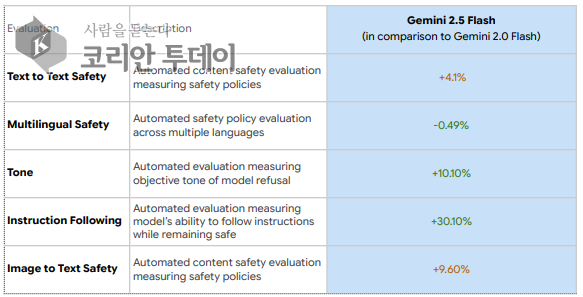 [코리안투데이] 제미나이 2.5 플래시 안전성 평가 (사진출처=구글) © 변아롱 기자 |
구글의 기술 보고서에 따르면, 제미나이 2.5 플래시는 ‘텍스트-텍스트 안전성(text-to-text safety)’에서 4.1%, ‘이미지-텍스트 안전성(image-to-text safety)’에서 9.6%의 성능 저하를 보였다. 이러한 평가는 자동화된 시스템을 통해 수행되었으며, 인적 감독 없이 실행되었다 .
오픈AI의 경우, o3와 o4-미니 모델이 이전 모델보다 환각(hallucination) 발생률이 높아졌다. 예를 들어, o4-미니는 PersonQA 벤치마크에서 0.48의 환각 점수를 기록했는데, 이는 o1의 0.16보다 약 세 배 높은 수치다 .
이러한 결과는 AI 모델이 사용자 지침을 더 충실히 따르도록 설계되면서, 민감한 주제에서도 지침을 지나치게 따르는 경향이 나타나고, 때로는 가이드라인을 넘는 ‘위반 콘텐츠’를 생성하는 경우도 있는 것으로 보고됐다. 구글은 이러한 문제에 대해 “민감한 주제에 대한 지침 준수와 안전성 정책 위반 사이에는 본질적으로 상충 관계가 있다”고 설명했다.
업계 전문가들은 AI 모델의 성능 향상이 반드시 안전성 향상으로 이어지지 않으며, 오히려 새로운 문제를 야기할 수 있다고 지적한다. AI 분석가 이선 몰릭(Ethan Mollick)은 이러한 현상을 ‘불규칙한 경계(jagged frontier)’라고 표현하며, “일부 작업에서는 AI가 신뢰할 수 없지만, 다른 작업에서는 초인적인 성능을 보인다”고 말했다.
이러한 상황에서 AI 기업들은 모델의 성능과 안전성 사이의 균형을 어떻게 맞출 것인지에 대한 고민이 필요하다. 또한, 사용자와 사회 전반의 신뢰를 얻기 위해서는 모델의 성능뿐만 아니라 안전성과 투명성에 대한 지속적인 개선이 요구된다.
[ 변아롱 기자 | yangcheon@thekoreantoday.com ]
<저작권자 ⓒ 코리안투데이(The Korean Today) 무단전재 및 재배포 금지>
")
